
How streaming, feedback, and governance turn algorithms into intelligence.
In Part I, we established that a Large Language Model is not Artificial Intelligence. LLMs generate text but AI systems generate outcomes. Now we’ll look at what makes those systems real: data flow, feedback, and accountability.
The Lifecycle of Real Intelligence
A genuine AI implementation is a closed-loop system. It doesn’t stop when the model outputs a prediction. It begins there.
Every iteration passes through five continuous phases:
Sense – collect signals from the world (transactions, sensors, logs, or user actions).
Infer – apply trained models to generate insights or decisions.
Act – trigger downstream events, notifications, or automated actions.
Observe – monitor the effect of those actions in real-time.
Adapt – update features, retrain, or tune parameters based on outcomes.
This cycle defines the difference between automation and intelligence. Automation executes. Intelligence learns.
Streaming: Where AI Meets Reality
In static batch learning, data is stale before the model ships. But the world is not static. Fraud patterns evolve, customers change, and sensors drift.
That’s where event-driven architectures come in. By using Apache Kafka as a durable event backbone, data becomes a continuous stream of state changes rather than snapshots.
Each event like a payment attempt, a sensor reading, a customer click can feed into a Flink streaming job that performs:
- Real-time feature extraction (e.g., rolling averages, time-since-last-event)
- Stateful aggregation (windowed statistics, anomaly flags)
- Low-latency model inference via embedded model servers
Instead of waiting for nightly ETL, intelligence happens inline, milliseconds after the event.
The Feedback Loop: Closing the Circuit
Static models degrade. To stay relevant, systems need feedback from ground truth and this is what actually happened after each prediction.
In Kafka/Flink-based architectures, this is often implemented as:
- Prediction Topic – where the system publishes its decisions.
- Outcome Topic – where later ground-truth data (e.g., transaction approved / rejected, sensor confirmed / failed) arrives.
- Join Stream – Flink job that continuously compares predictions with outcomes, computes accuracy metrics, and feeds a model-drift detector.
Once drift or performance decay is detected, a retraining trigger can automatically start a new training pipeline, or flag a human reviewer.
This loop
data → model → decision → feedback → retraining
is what turns machine learning into continuous learning.
The Governance Layer
Intelligence without governance is entropy.
Modern AI systems must record:
- Versioned datasets (to reproduce any decision)
- Model lineage (which data, which hyperparameters, which code)
- Policy enforcement (who can deploy or approve changes)
Technologies like MLflow, Feast, or OpenLineage, combined with stream-native audit trails in Kafka, make this traceability possible.
In regulated environments like for example finance, healthcare or the public sector these controls are not optional. They are the foundation of trustable AI.
Self-Training for Domain Purpose
The holy grail is domain-adaptive AI where the systems that improve on proprietary data while staying compliant and explainable.
That means retraining pipelines that:
- Consume real-time data streams as labeled examples.
- Write intermediate states to an online feature store (for inference) and an offline store (for training).
- Evaluate new models against live baselines before promotion.
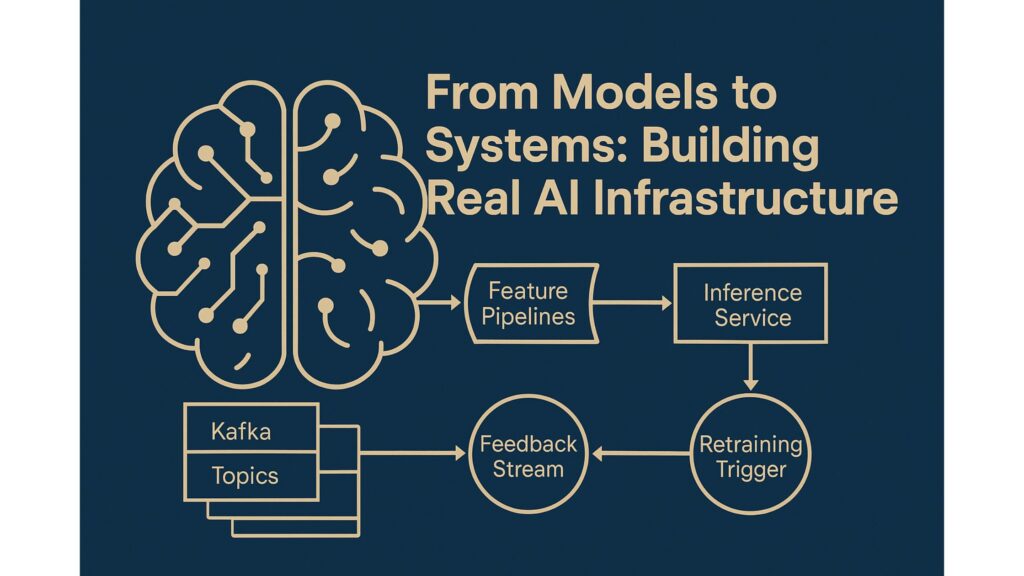
In practice, this architecture often looks like:
[Kafka Topics] → [Flink Feature Pipelines] → [Model Store] → [Inference Service] → [Feedback Stream] → [Retraining Trigger]Each component has a clear contract, making the system maintainable, observable, and evolvable.
From Hype to Engineering
True AI is not the art of prompt crafting. It’s the discipline of data-driven systems design. It’s about error budgets, SLA-aware inference, schema evolution, and reproducibility. It’s what happens after the demo — when the model must survive drift, downtime, and regulators.
LLMs can augment these systems. But maybe as copilots and not as pilots.
But the cockpit is still built from data pipelines, stream processors, and feedback control.
Conclusion
If Part I exposed the myth, Part II defines the method.
Intelligence emerges not from the model’s size but from the system’s ability to learn, correct, and endure.
Real AI is an ecosystem and not a prompt, not a dashboard, not a slide. It’s a living infrastructure where data, models, and humans form a continuous learning loop.
And that loop, not the next token, is where the future of intelligence begins.